机器学习是人工智能的一种形式,其旨在提高设备的智能化水平。创新的软件功能通常采用机器学习创建的软件制品来实现。机器学习能够快速识别模式,这对于汽车电子领域来说是一项极为重要的能力。
应用程序、功能软件、传感器和执行器都能借助机器学习模型快速识别模式的能力,这种能力远超人类。高级驾驶辅助系统、自动驾驶系统以及诸如预测设备磨损情况等其他系统,都离不开这些强大的功能。
Automotive SPICE过程评估模型(PAM) 4.0版中的“机器学习工程”过程组,以及ISO/IEC 23053:2022等标准,明确了如何在符合安全性和可靠性标准的汽车电子产品开发环境中使用机器学习应用程序。该标准不仅丰富并拓展了Automotive SPICE的应用场景,还为质量开发提供了有力支持,并为功能安全、预期功能安全(SOTIF)和网络安全筑牢了根基。
机器学习基础
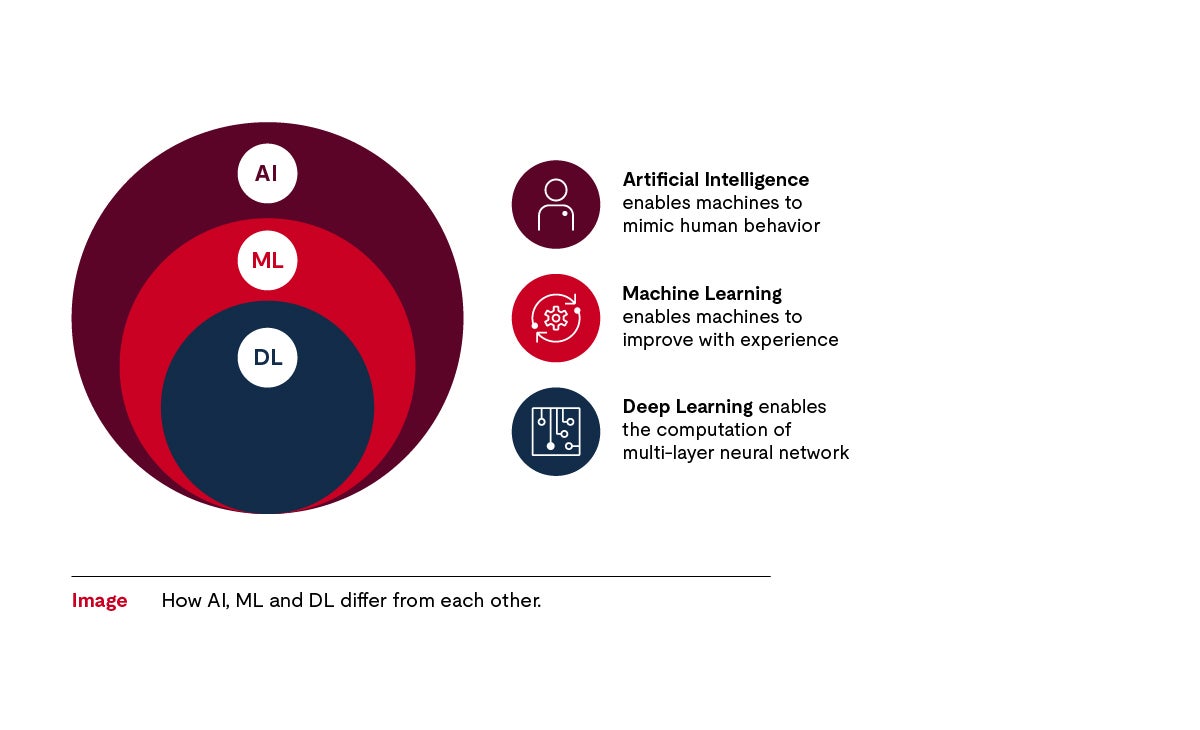
人工智能在文献中有很多种解释和分类。人工智能是深度学习和机器学习的总称,其与现有应用程序相关并且存在于很多应用程序中,例如聊天机器人。
聊天机器人采用预先训练好的语言模型 - 通常是利用无监督学习技术进行大量文本数据训练的大型神经网络。凭借这一庞大的数据语料库,聊天机器人能够依据静态概率来回答人类提出的问题。
机器学习属于人工智能的一个子集,机器学习也会使用基于预先提供的数据创建的算法。这些算法能够使机器(如应用软件或组件)更加强大。例如,在汽车电子领域,通过机器学习可实现对交通标志的识别和解读。
深度学习属于机器学习的一个子集,深度学习利用更为复杂的算法和神经网络来模拟大脑神经元结构。
通过机器学习解决基于模式的问题
机器学习擅长解决那些可以使用模式来解释的问题。开发人员或组织必须先收集大量的样本数据,例如交通标志。随后算法会将数据集中的非结构化信息转换为标准化格式。
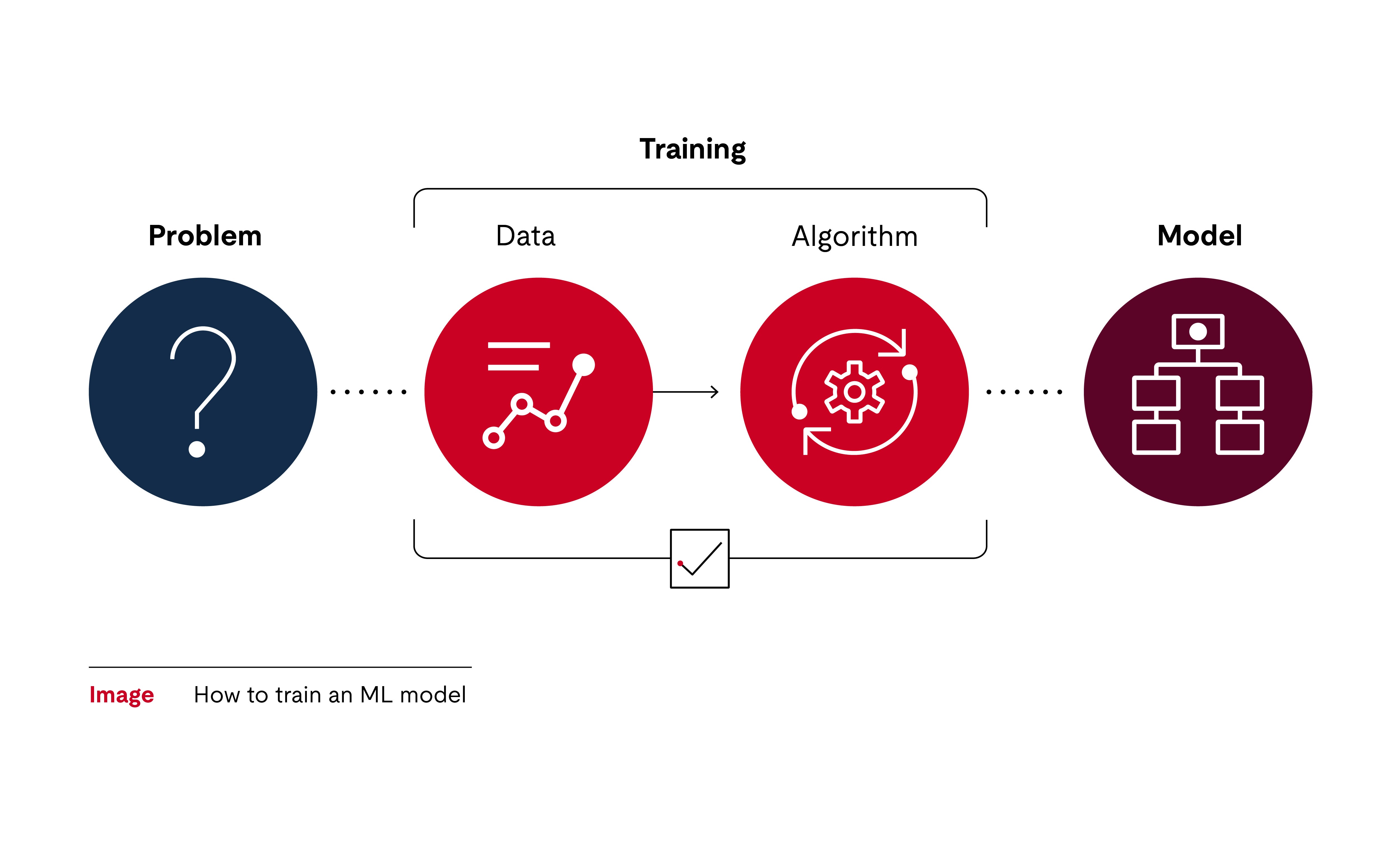
从机器学习工程的角度来看,重要的一点是,这个软件产品不是由人类编程完成的。算法通过训练过程实现自我优化和完善。经过这一过程后,算法会尝试作出近似行为,并从诸多示例中学习有意义的模式。实际上能够达到目标的算法不是只有一种,而是有无数种。机器学习工程师会选用其中理想的算法。
算法能够自主从数据集中提取指令。这一过程被称作机器学习,是因为算法可以自行学习如何将给定的数据整理成有用的信息。为了让训练达到预期效果,算法会从工程学的角度被引导如何理解环境。以交通标志识别为例,算法会通过分析颜色分布来检测模式,并据此推断出最有可能的交通标志名称。
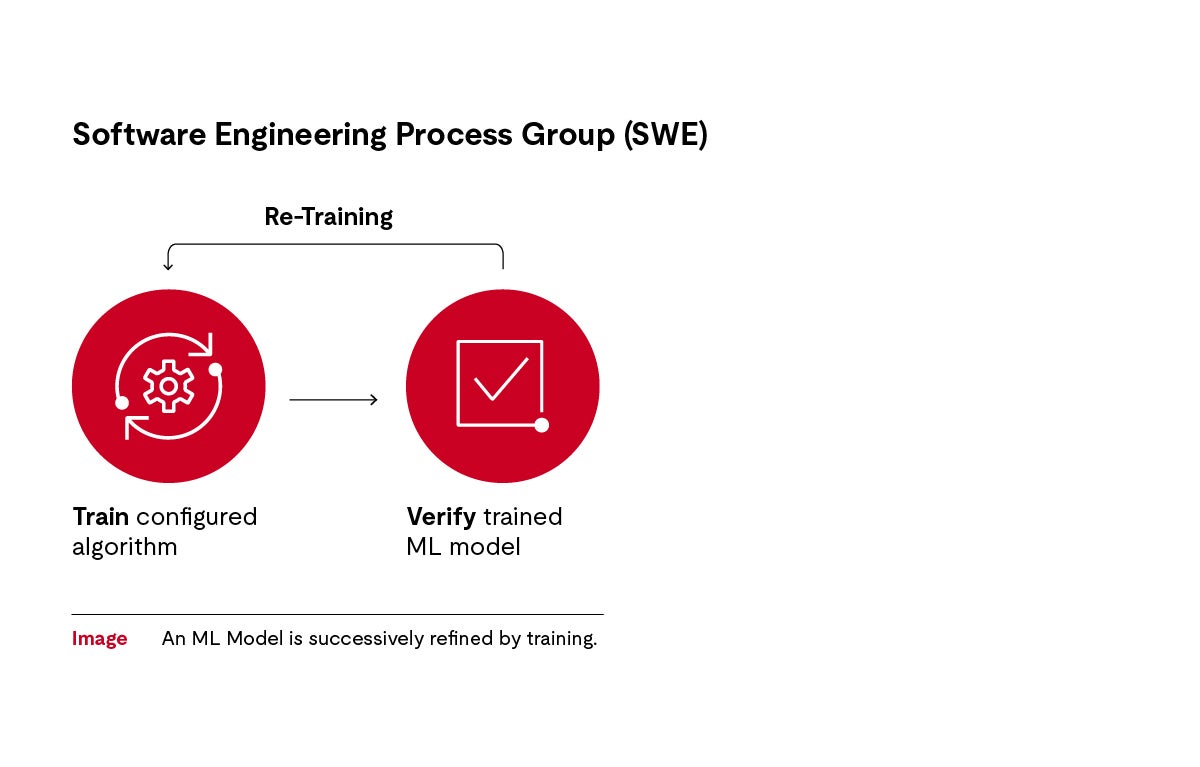
这一训练过程是迭代式的,采用反复试错的方法逐步优化。机器学习工程师会定期检查算法是否能够正确地将训练数据进行结构化处理,并将结构化后的数据准确分配到对应的交通标志名称。随后,工程师会引入更多的训练材料来进一步改进算法,并重复这一过程,直到获得一个稳健可靠的模型结果。最终,工程师会将新的数据提供给算法,并检查其输出结果,以确保模型的准确性和可靠性。
模型是包含有关信息的资产。模型可在应用软件中实现。在我们的示例中,模型包含有一个决策树,通过该决策树我们可以了解到图像颜色如何与不同的交通标志相关联。
通过独立的数据集验证模型,确保模型的训练依据不是数据,而是实际环境中可能出现的情况。
因为软件并非由人工编写,这就形成了一个“黑箱”。算法生成了一个结果——即模型。然而,要以合理的方式理解这个模型的结构几乎是不可能的,这就给我们带来了在安全关键系统中编写可靠软件的挑战,因为我们并不清楚它是如何工作的。从质量保证的角度来看,这是不可接受的。
考虑到机器学习的开发方法有其特殊性,因此随着机器学习模型引入汽车软件和后端,我们在质量、功能安全和网络安全方面都会面临新的挑战。
Automotive SPICE等标准提供的传统过程不能与机器学习结合使用。在传统开发中,您需要先明确需求——即软件需要实现什么功能。接着设计架构——即如何组织软件以实现这些功能。然后,针对每个单元,定义代码中需要实现的具体细节。最后,基于这些细节开展一系列测试。
在机器学习中,没有这样的形式化测试。一旦开发人员对满足预定义标准的结果感到满意,便会测试并发布算法。因此,机器学习的验证和测试主要基于数据标记、训练和防偏差,同时确保符合关键绩效指标(KPI)。
这里可以打个比方,从质量保证的角度,将训练、验证和测试过程想象成洋葱的层层结构,由此说明已确定的顺序和依赖性。
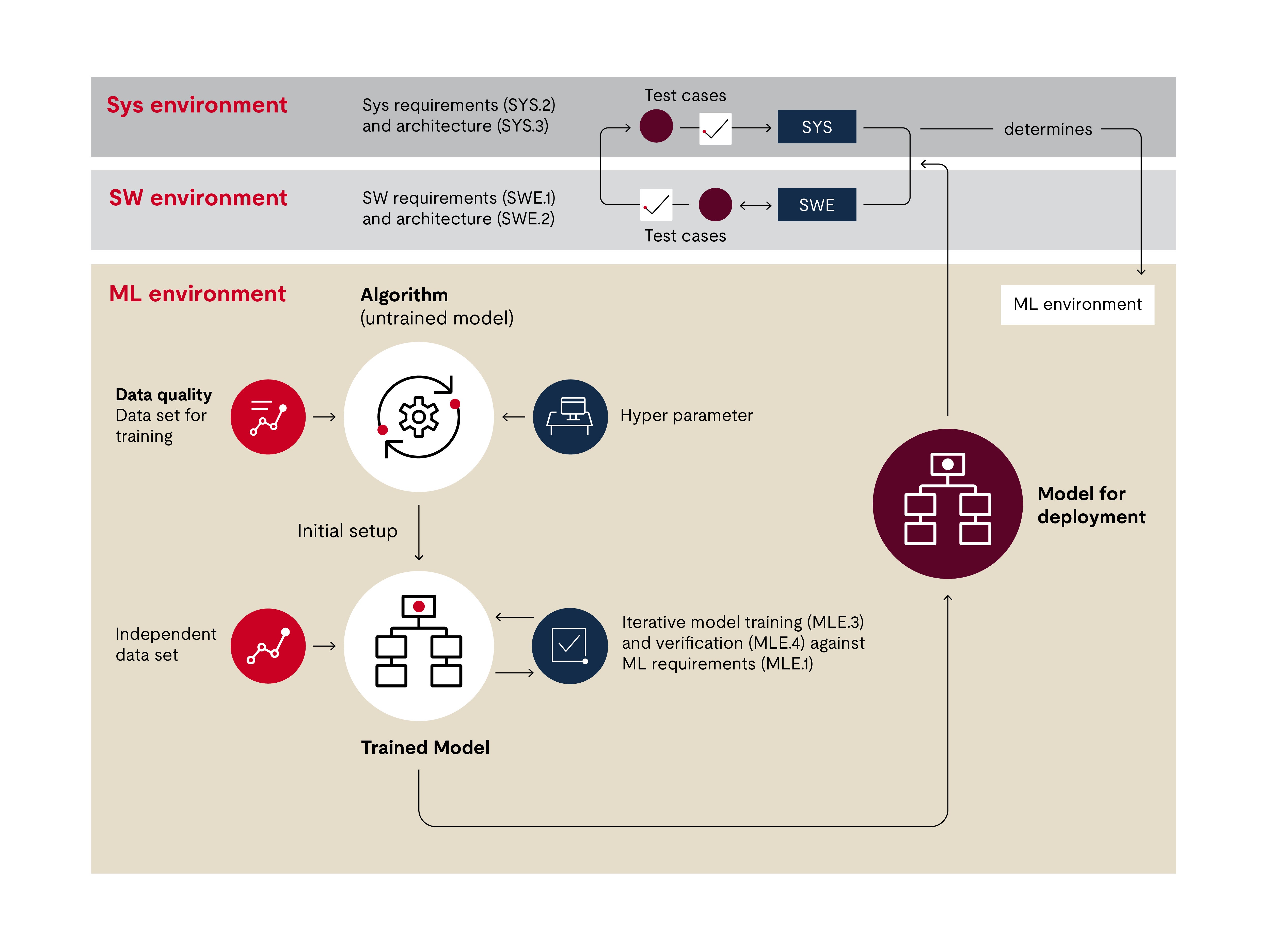
洋葱的内层为算法。机器学习工程师已根据所需功能对算法进行了配置。通过该定制可以控制神经连接数量或节点数量。如果需要对算法进行更新,则需要进行新的训练和验证。两个层面共同作用形成了训练模型。随后该模型还会从这两个层面进行测试。
由于该模型基于训练数据,因此数据质量非常关键。在洋葱图中,我们可以看到有一个独立的数据处理过程。
对Automotive SPICE应用机器学习工程模型
通过机器学习创建软件制品的过程属于软件工程过程。因此,Automotive SPICE标准是以软件工程过程为基础的。待开发软件的需求在需求过程(SWE.1)中确定,这适用于所有汽车电子软件。为此,需要将相关的系统需求转化为一组软件需求,其中一些需求涉及使用机器学习来创建软件制品。软件架构作为软件架构设计(SWE.2)的结果,规定了其具体内容。
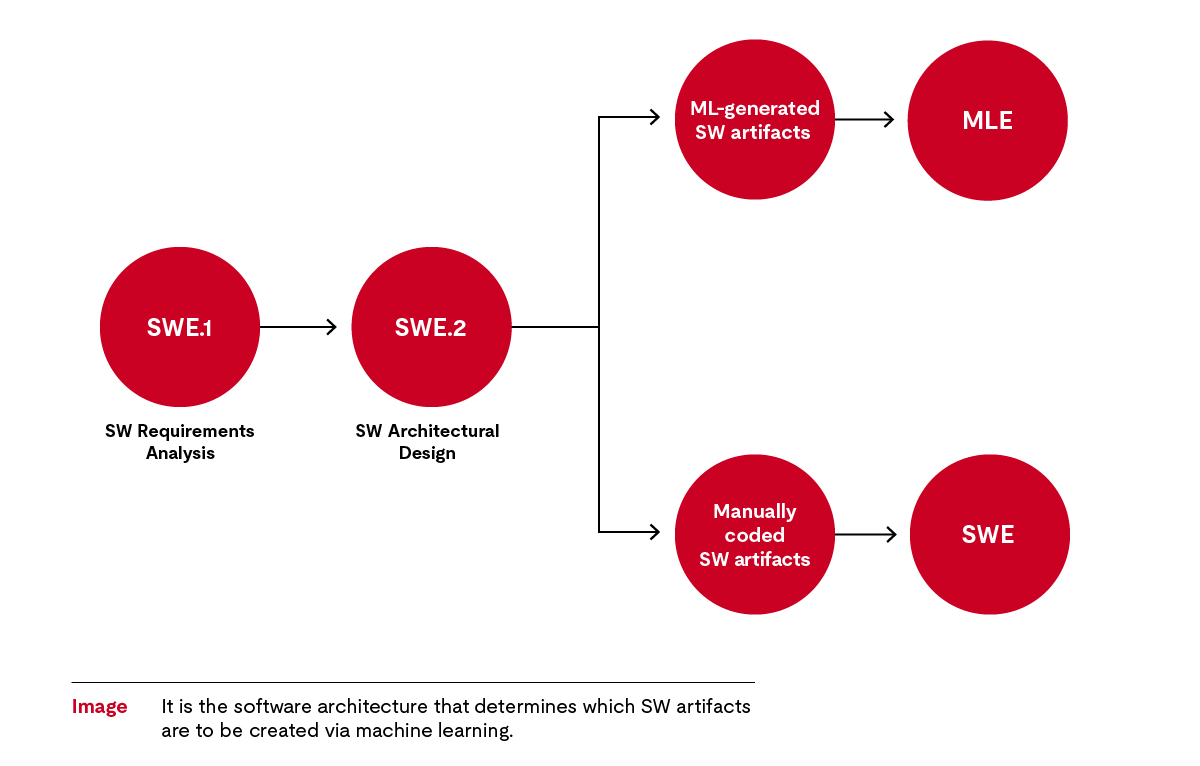
在机器学习领域,软件制品是由算法生成的,因此我们需要能够替代经典软件详细设计的特殊过程。
在下面的图表中,V模型的左上角是机器学习需求分析过程(MLE.1)。此过程的任务是从软件需求中确定机器学习的特殊需求。
紧接着是机器学习架构(MLE.2)。此过程涉及到为训练和创建算法以及其他必要的软件(如预处理和后处理软件)提供支持的机器学习架构。
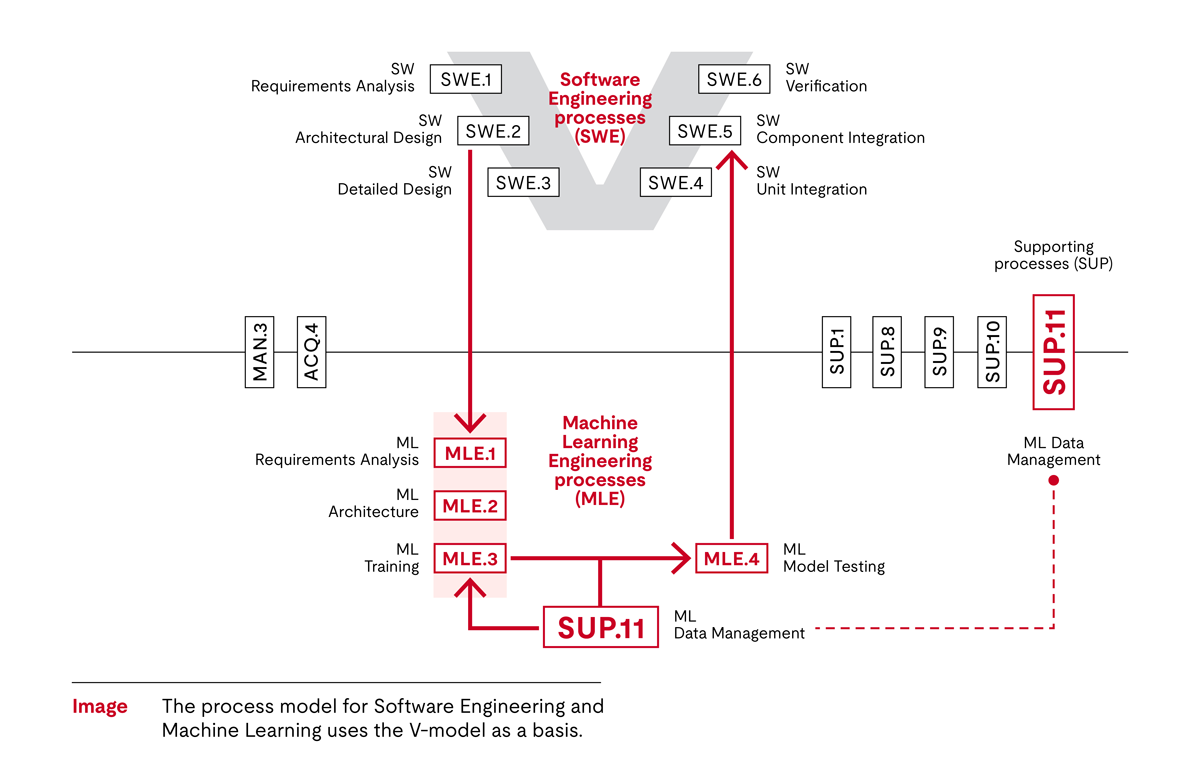
V模型的右侧是算法训练。需要注意的是模型不仅要执行,而且重要的是要满足指定的需求(MLE.3)。如上文所述,训练是一种系统的、反复试错的方法。
在测试过程中,必须确保训练的机器学习模型和实现的机器学习模型均符合机器学习需求规格(MLE.4)。我们会将经过验证的训练模型与可用于系统实际软件的部署模型区分开来。
随后,在软件集成测试(SWE.5)中,将相关制品集成在一起并进行测试。此时相关制品,无论是以传统方式编码的制品还是使用机器学习方法进行训练的制品,都会聚集在一起。
然而,测试范围并不包括数据质量。新的支持过程,“机器学习数据管理”(SUP.11),会根据机器学习数据要求,定义与机器学习相关的数据,并保证数据完整性。
数据管理是一项非常复杂的任务,通常由组织内的专业大型团队负责,因此会专门采用独立的数据管理过程评估模型来进行管理。
在Automotive SPICE 4.0版中,机器学习属于该标准的一部分。与传统开发软件相结合后,现在可以从质量角度进行机器学习开发。由此也为功能安全和网络安全奠定了良好基础。
为什么选择UL Solutions Software Intensive Systems作为Automotive SPICE支持服务提供商?
作为系统化改进汽车电子领域开发过程战略的一部分,UL Solutions Software Intensive Systems已获得德国汽车工业协会(VDA QMC) Automotive SPICE商标正式使用许可。
我们能够在以下方面为主机厂(OEM)及其供应商提供全方位的支持:
- 在关键开发过程中达到所需的能力级别。
- 系统化改进现有工作流程和方法。
- 通过正式评估和差距分析来评估过程改进状态。
- 满足Automotive SPICE的要求,同时兼顾安全、功能安全和敏捷方法。
- 培训员工和审核员。
X
联系我们
感谢您对我们产品和服务的关注。为了更好地为您服务,我们将收集一些信息,以便为您安排合适的人员与您联系。
Please wait…
剩余字符